Join은 sql의 시작과 끝
실무를 하다보면 결국 join (inner join)과 left join 을 가장 많이 쓰게 되는데 실제 데이터와 쿼리를 보면서 어떤식으로 결과가 나오는지 확인해본다.
데이터는 Join을 이해하기 쉽도록 포인트 적립과 사용에 대한 데이터를 예제로 사용해본다.
데이터 준비
- write (DDL) 쿼리가 안되는 환경을 고려해서 다음과 같이 데이터를 넣는다.
상황 : AA, BB 두명의 유저가 있고 포인트를 쌓거나 사용하고 있으며 각각 get_point, use_point에 로그를 남긴다. .
point 테이블 : 간단하게 idx(index, Primary Key값, 고유번호를 의미하는 컬럼)만 넣은 테이블
get_point 테이블 : 포인트 적립 (p_idx, idx, uid, point) , p_idx로 point.idx와 엮을 수 있다.
use_point 테이블 : 포인트 사용 (p_idx, idx, uid, point) , p_idx로 point.idx와 엮을 수 있다.
*원래 idx , p_idx , uid, point 순서가 더 자연스러운데 중간에 수정하다보니.. 글을 전체 수정하기 어려워서 이대로 감.
with point as (
select 1 IDX union all
select 2 union all
select 3 union all
select 4 union all
select 5 union all
select 6 union all
select 7 union all
select 8 union all
select 9 union all
select 10 union all
select 11 union all
select 12 union all
select 13 union all
select 14 union all
select 15 union all
select 16
)
,get_point as (
select 1 p_IDX, 1 IDX, 'AA' UID, 1000 POINT union all
select 2 , 2 , 'AA' , 1500 union all
select 3 , 3 , 'BB' , 1000 union all
select 4 , 4 , 'AA' , 1000 union all
select 6, 5 , 'BB' , 2000 union all
select 7, 6 , 'AA' , 500 union all
select 10, 7 , 'BB' , 5000 union all
select 11, 8 , 'AA' , 10000 union all
select 15, 9 , 'BB' , 3000 union all
select 16, 10 , 'AA' , 5000
)
,use_point as (
select 5 p_IDX, 1 IDX, 'AA' UID, -1500 POINT union all
select 8, 2 , 'AA' , -200 union all
select 9, 3 , 'BB' , -100 union all
select 12, 4 , 'AA' , -100 union all
select 13, 5 , 'BB' , -2800 union all
select 14, 6 , 'AA' , -500
)
데이터 확인
- point 테이블
select * from point p
- get_point 테이블
select * from get_point gp
- use_point 테이블
select * from use_point up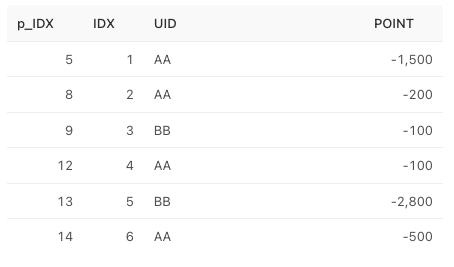
inner join 결과
이때, 만약 전체를 join 한다면?
select * from point p
join get_point gp on gp.p_idx = p.idx
join use_point up on up.p_idx = p.idx=> 아무것도 나오지 않는다.
호옥..시 point.idx별로 join 이 되어서 전체 적립/사용 테이블이 나오길 기대했나?
아니다. 그걸 보기 위해서는 Left join 으로 처리해야한다.
left join 결과
select * from point p
Left join get_point gp on p.idx=gp.p_idx
left join use_point up on p.idx=up.p_idx이렇게 했더니 원하는 것을 볼 수 있게 되었다.

case when 사용해서 정리하기
위 쿼리의 결과로 나온 테이블은 뭔가 정리가 안 되어 있음. 원하는것에 아직 한발 부족함.
그럴때는 case when을 사용함.
먼저 위의 Left join 두개 사용한 쿼리를 With 문으로 서브쿼리로 만들어 주고, 해당 테이블을 다시 사용하면서 case 문을 이용하는 방식
,tbl as (
select p.idx,
gp.idx gp_idx, gp.p_idx gp_p_idx, gp.uid gp_uid, gp.point gp_point,
up.idx up_idx, up.p_idx up_p_idx, up.uid up_uid, up.point up_point
from point p
left join get_point gp on p.idx=gp.p_idx
left join use_point up on p.idx=up.p_idx
)
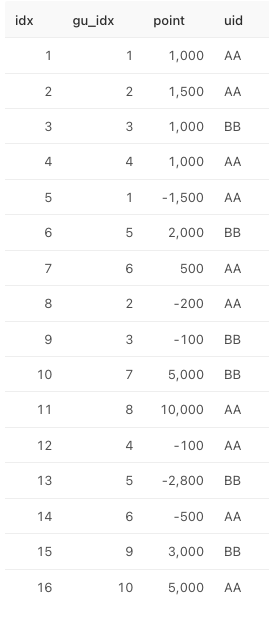
select tbl.idx,
case when gp_idx is not null then gp_idx else up_idx end gu_idx,
case when gp_idx is not null then gp_point else up_point end point,
case when gp_idx is not null then gp_uid else up_uid end uid
from tbl그럼 요렇게 나온다.
'sql' 카테고리의 다른 글
| sql 윈도우 함수 count over partition by (Feat.리트코드) (0) | 2023.01.25 |
|---|---|
| 인덱스 잘 타네요 라고 말할 수 있는 사람 되는 법 (1탄. 인덱스란?) (0) | 2023.01.19 |
| mysql 누적집계 sum over (0) | 2022.12.26 |